

Benefits of data modelling
Data modelling offers numerous benefits to various stakeholders within an organisation. It provides developers, data architects, business analysts, and other stakeholders with a clear and comprehensive view of the relationships between data in a database or data warehouse.
- Reducing errors during software and database development
- Ensuring consistency in documentation and system design across the enterprise
- Improving application and database performance
- Data modelling facilitates data mapping integrating all areas of the organisation
- Enhances communication between developers and business intelligence teams
- Expedites the process of database design at the conceptual, logical, and physical levels.
What is Data modelling?
Data modelling is creating visual representations of data flows. When designing a new or modified database structure, the designer begins by creating a diagram that illustrates how data will enter and exit the database. This diagram serves as a blueprint for determining the data formats, structures, and database functions needed to effectively support the data flow requirements. Even after the database is built and implemented, the data model continues to serve as documentation and rationale for the existence of the database and the design of its data flow.
The resulting data model defines the relationships between the data elements in a database and also provides guidance on how to use the data.
Data models are a fundamental part of software design and analysis. They define and format database content in a consistent manner across systems, allowing different applications to work with the same information.
What is the importance of data modelling?
A well-structured and optimised data model helps to create a streamlined, organised database that eliminates redundancies, minimises storage needs, and facilitates efficient retrieval. Additionally, it gives all systems access to a single source of truth – essential for efficient operations and compliance with laws and regulations.
The Data Modeling Process
Data modelling is a process that encourages stakeholders to assess the processing and storage of data in detail. Different data modelling techniques have their own conventions that determine the symbols used to represent data, the layout of models, and how to communicate business requirements. All data modelling approaches provide formalised workflows that involve a series of tasks that must be completed in a sequential manner. These workflows typically look something like:
- Entities – The process of data modelling starts with identifying the things, events, or concepts that are included in the data set to be modelled. Every entity should be consistent and logically distinct from others.
- Key Entity Properties – Identify key characteristics of each entity. Every entity type can be distinguished from others by having one or more unique characteristics, known as attributes. For example, an entity called “customer” may have attributes such as “first name,” “last name,” “phone number,” and “salutation,” while an entity called “address” may have attributes like “street name and number,” “city,” “state,” and “postcode”.
- Relationships – Identify relationships between entities. The first draft of the data model will define the relationships between each entity and the others. For example, in the example above, each customer “lives at” an address. If the model were to be expanded to include “orders,” each order “shipped” and “billed” to an address. These relationships are typically documented in UML.
- Mapping – Completely map attributes to entities. This will ensure that the model accurately reflects how the business uses the data. There are several formal data modelling patterns that are commonly used by object-oriented developers, analysis patterns, or design patterns. Stakeholders from other business areas may use other patterns.
- Keys – Add keys as needed. Decide on a level of normalisation that meets the need to minimise redundancy while still meeting performance requirements. Normalisation is a way to organise data models (and databases they represent) by assigning numerical identifiers, known as keys, to groups of data. These keys represent relationships between data sets without repeating data. For example, if each customer is assigned a key, the key can be used to link both the customer’s address and the customer’s order history without repeating this information in the customer name table. Normalisation usually reduces the size of the database, but it can come at a price in terms of query performance.
- Verify and repeat the data model – Data modelling is iterative and should be repeated and improved as business needs evolve.
Types of data models
Est ac eu placerat urna ullamcorper euismod. Orci sit enim facilisis lacus sollicitudin justo adipiscing netus. Magna orci quis dictum ipsum leo tristique nisl adipiscing.
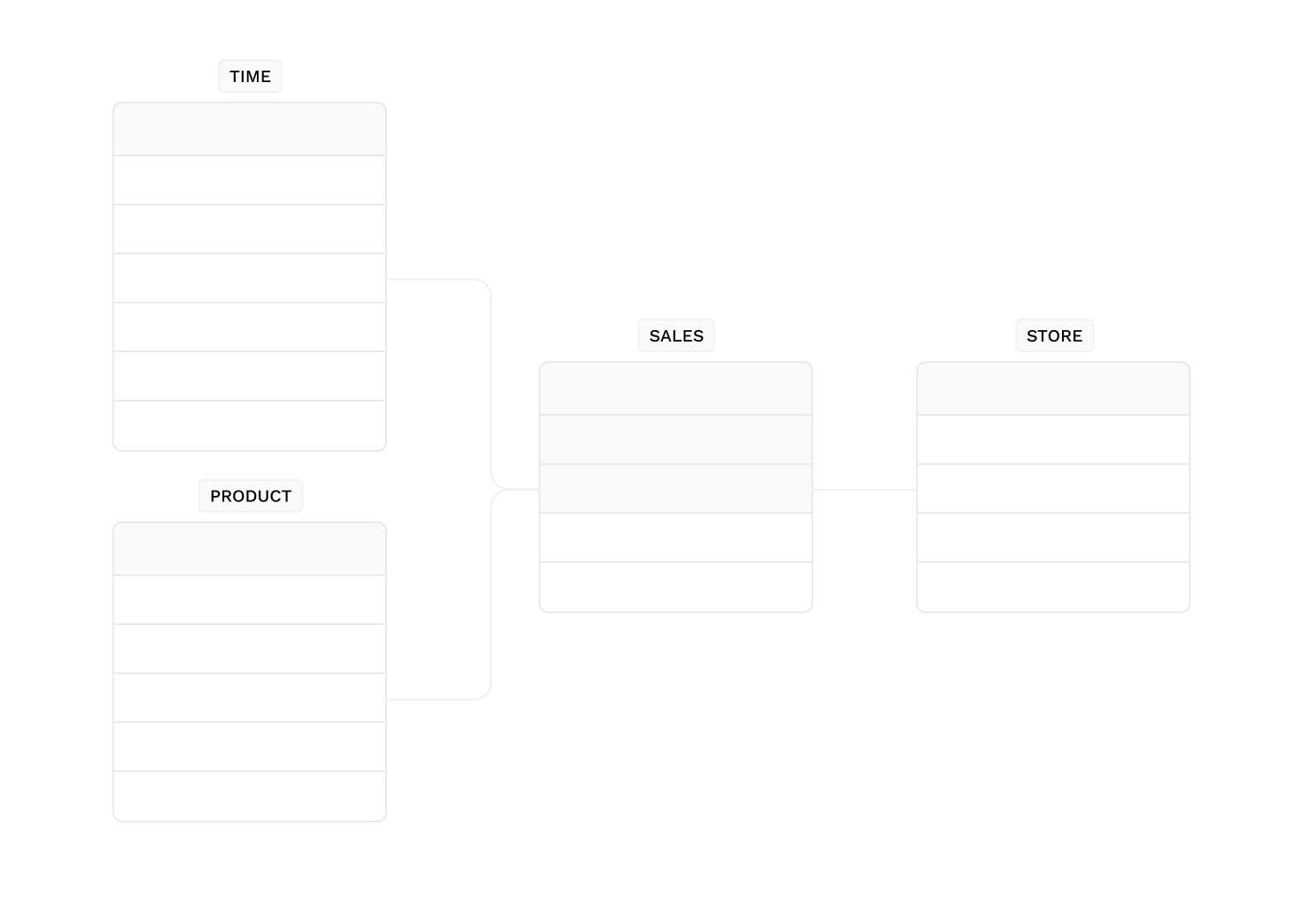
Conceptual data models
Also known as domain models, conceptual models provide a broad view of the system’s content, structure, and business rules. They are typically developed as part of the initial project requirements gathering. Conceptual models typically include entity classes (defined as the types of things important for a business to represent in a data model), their properties and limitations, relationships between them, and related security and data integrity considerations. Any notation is usually straightforward.
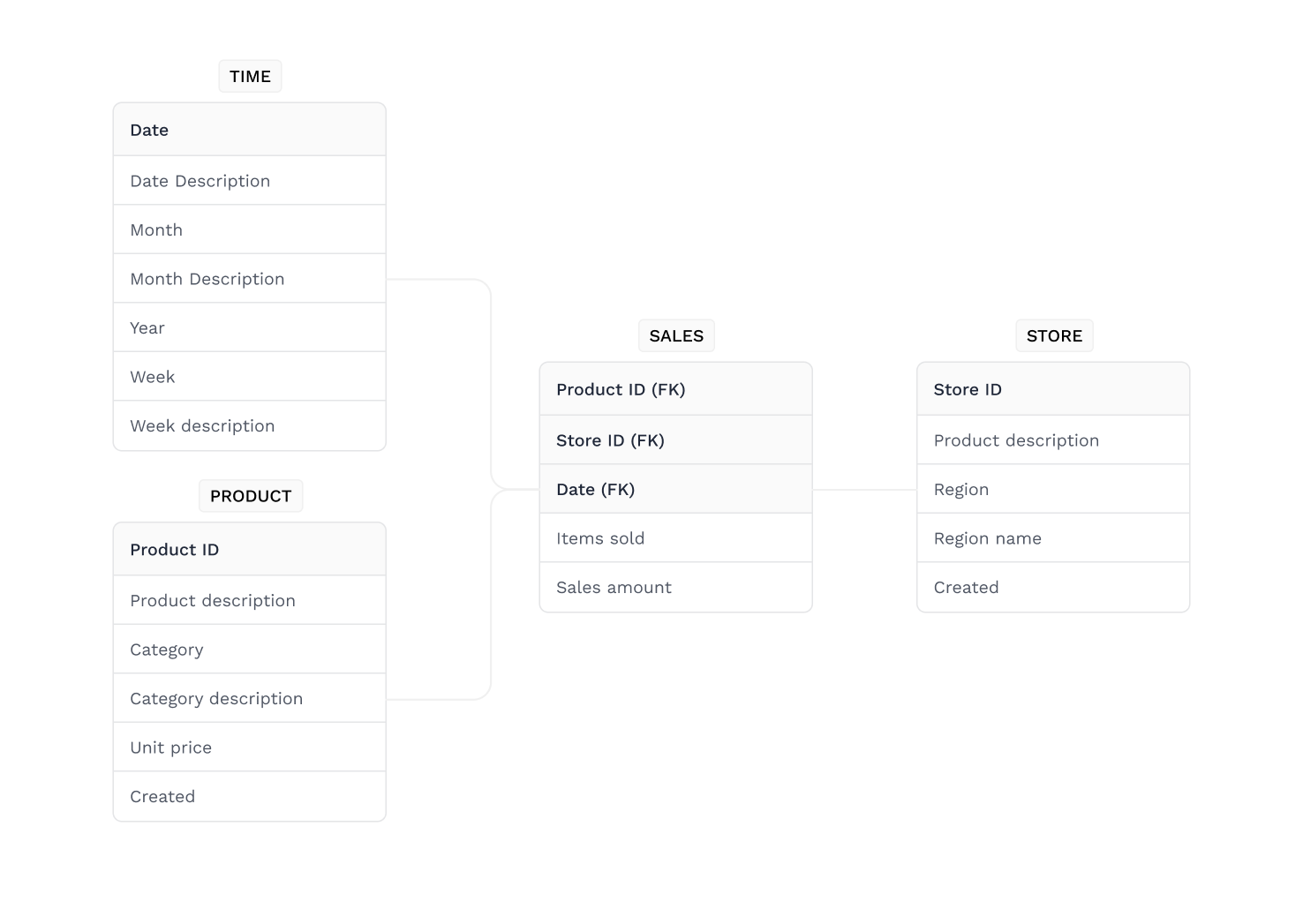
Logical data models
Logical data models are less abstract and describe the concepts and relationships of the domain in greater detail. They use one of the many data modelling notation systems and display data attributes like data types and their associated lengths, as well as the relationships between entities. Logical models do not specify technical system requirements and are often overlooked in agile or DevOps practices. They are useful for highly procedural implementation environments or for data-oriented projects such as designing a data warehouse or developing a reporting system.
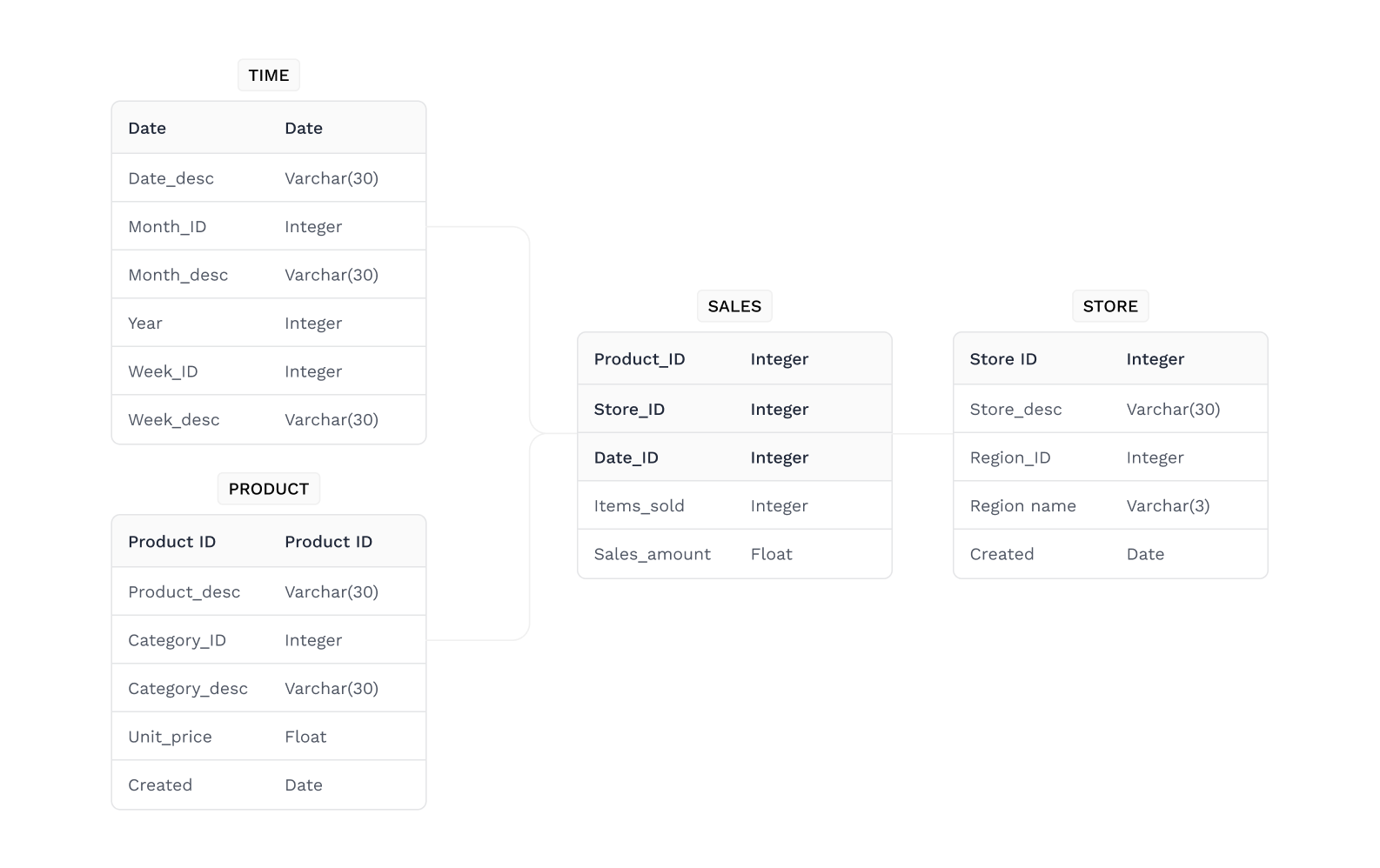
Physical data models
Physical data models are the least abstract of the three and provide a final design that can be used as a relational database. They include associative tables that show the relationships between entities and the primary keys and the foreign keys that will maintain those relationships. These physical data models can include DBMS-specific properties, such as performance tuning. They provide a schema for how the data will be physically stored.